Tutorial: A simple restaurant search bot¶
Note
See Migrating an existing app for how to clone your existing wit/LUIS/Dialogflow app.
As an example we’ll start a new project covering the domain of searching for restaurants. We’ll start with an extremely simple model of those conversations. You can build up from there.
Let’s assume that anything our bot’s users say can be categorized into one of the following intents:
greetrestaurant_searchthankyou
Of course there are many ways our users might greet our bot:
- Hi!
- Hey there!
- Hello again :)
And even more ways to say that you want to look for restaurants:
- Do you know any good pizza places?
- I’m in the North of town and I want chinese food
- I’m hungry
The first job of Rasa NLU is to assign any given sentence to one of
the intent categories: greet, restaurant_search, or thankyou.
The second job is to label words like “Mexican” and “center” as
cuisine and location entities, respectively.
In this tutorial we’ll build a model which does exactly that.
Preparing the Training Data¶
The training data is essential to develop chatbots. It should include texts to be interpreted and the structured data (intent/entities) we expect chatbots to convert the texts into. The best way to get training texts is from real users, and the best way to get the structured data is to pretend to be the bot yourself. But to help get you started, we have some data saved.
Download the file (json format) and open it, and you’ll see a list of
training examples, each composed of "text", "intent" and
"entities", as shown below. In your working directory, create a
data folder, and copy this demo-rasa.json file there.
{
"text": "hey",
"intent": "greet",
"entities": []
}
{
"text": "show me chinese restaurants",
"intent": "restaurant_search",
"entities": [
{
"start": 8,
"end": 15,
"value": "chinese",
"entity": "cuisine",
"confidence": 0.875
}
]
}
Hopefully the format is intuitive if you’ve read this far into the tutorial, for details see Training and Data Format. Otherwise, the next section ‘visualizing the training data’ can help you better read, verify and/or modify the training data.
Visualizing the Training Data¶
It’s always a good idea to look at your data before, during, and after training a model. Luckily, there’s a great tool for creating training data in rasa’s format. - created by @azazdeaz - and it’s also extremely helpful for inspecting and modifying existing data.
For the demo data the output should look like this:
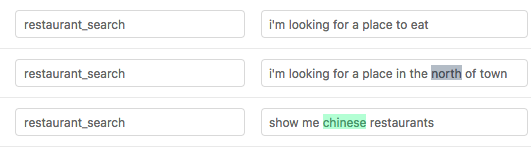
It is strongly recommended that you view your training data in the GUI before training.
Training a New Model for your Project¶
Now we’re going to create a configuration file. Make sure first that
you’ve set up a backend, see Installation. Create a file
called config_spacy.yml in your working directory which looks like this
language: "en"
pipeline: "spacy_sklearn"
or if you’ve installed the MITIE backend, you can use the following as your base configuration:
language: "en"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat"
- name: "tokenizer_mitie"
- name: "ner_mitie"
- name: "ner_synonyms"
- name: "intent_entity_featurizer_regex"
- name: "intent_classifier_mitie"
Now we can train a spacy model by running:
$ python -m rasa_nlu.train \
--config sample_configs/config_spacy.yml \
--data data/examples/rasa/demo-rasa.json \
--path projects
What do these parameters mean?
- config: configuration of the machine learning model
- data: file or folder that contains the training data. You can also
pull training data from a URL using --url instead.
- path: output path where the model is persisted to
If you want to know more about the parameters, there is an overview of the
Configuration. After a few minutes, Rasa NLU will finish
training, and you’ll see a new folder named as
projects/default/model_YYYYMMDD-HHMMSS with the timestamp
when training finished.
Using Your Model¶
By default, the server will look for all projects folders under the path
directory specified. When no project is specified, as in this example,
a “default” one will be used, itself using the latest trained model.
$ python -m rasa_nlu.server --path projects
More information about starting the server can be found in Using Rasa NLU as a HTTP server.
You can then test your new model by sending a request. Open a new window on your terminal and run
Note
For windows users the windows command line interface doesn’t
like single quotes. Use doublequotes and escape where necessary.
curl -X POST "localhost:5000/parse" -d "{/"q/":/"I am looking for Mexican food/"}" | python -m json.tool
$ curl -X POST localhost:5000/parse -d '{"q":"I am looking for Mexican food"}' | python -m json.tool
which should return
{
"intent": {
"name": "restaurant_search",
"confidence": 0.8231117999072759
},
"entities": [
{
"start": 17,
"end": 24,
"value": "mexican",
"entity": "cuisine",
"extractor": "ner_crf",
"confidence": 0.875
}
],
"intent_ranking": [
{
"name": "restaurant_search",
"confidence": 0.8231117999072759
},
{
"name": "affirm",
"confidence": 0.07618757211779097
},
{
"name": "goodbye",
"confidence": 0.06298664363805719
},
{
"name": "greet",
"confidence": 0.03771398433687609
}
],
"text": "I am looking for Mexican food"
}
If you are using the spacy_sklearn backend and the entities aren’t
found, don’t panic! This tutorial is just a toy example, with far too
little training data to expect good performance.
Note
Intent classification is independent of entity extraction, e.g. in “I am looking for Chinese food” the entities are not extracted, though intent classification is correct.
Rasa NLU will also print a confidence value for the intent
classification. For models using spacy
intent classification this will be a probability.
You can use this to do some error handling in your chatbot (ex: asking the user again if the confidence is low) and it’s also helpful for prioritising which intents need more training data.
Note
The output may contain other or less attributes, depending on the
pipeline you are using. For example, the mitie pipeline doesn’t
include the "intent_ranking" (see example below) whereas the
spacy_sklearn pipeline does (see example above).
With very little data, rasa NLU can in certain cases already generalise concepts, for example:
$ curl -X POST localhost:5000/parse -d '{"q":"I want some italian food"}' | python -m json.tool
{
"intent": {
"name": "restaurant_search",
"confidence": 0.5792111723774511
},
"entities": [
{
"entity": "cuisine",
"value": "italian",
"start": 12,
"end": 19,
"extractor": "ner_crf",
"confidence": 0.875
}
],
"text": "I want some italian food"
}
even though there’s nothing quite like this sentence in the examples used to train the model. To build a more robust app you will obviously want to use a lot more training data, so go and collect it!