Training Data Format¶
Data Format¶
You can provide training data as markdown or as json, as a single file or as a directory containing multiple files. Note that markdown is usually easier to work with.
Markdown Format¶
Markdown is the easiest Rasa NLU format for humans to read and write.
Examples are listed using the unordered
list syntax, e.g. minus -, asterisk *, or plus +.
Examples are grouped by intent, and entities are annotated as markdown links.
## intent:check_balance
- what is my balance <!-- no entity -->
- how much do I have on my [savings](source_account) <!-- entity "source_account" has value "savings" -->
- how much do I have on my [savings account](source_account:savings) <!-- synonyms, method 1-->
## intent:greet
- hey
- hello
## synonym:savings <!-- synonyms, method 2 -->
- pink pig
## regex:zipcode
- [0-9]{5}
The training data for Rasa NLU is structured into different parts: examples, synonyms, and regex features.
Synonyms will map extracted entities to the same name, for example mapping “my savings account” to simply “savings”. However, this only happens after the entities have been extracted, so you need to provide examples with the synonyms present so that Rasa can learn to pick them up.
JSON Format¶
The JSON format consist of a top-level object called rasa_nlu_data, with the keys
common_examples, entity_synonyms and regex_features.
The most important one is common_examples.
{
"rasa_nlu_data": {
"common_examples": [],
"regex_features" : [],
"entity_synonyms": []
}
}
The common_examples are used to train your model. You should put all of your training
examples in the common_examples array.
Regex features are a tool to help the classifier detect entities or intents and improve the performance.
Visualizing the Training Data¶
If you’re using the json format, it’s always a good idea to look at your data before, during, and after training a model. Luckily, there’s a great tool for creating training data in rasa’s format. - created by @azazdeaz - and it’s also extremely helpful for inspecting and modifying existing data.
For the demo data the output should look like this:
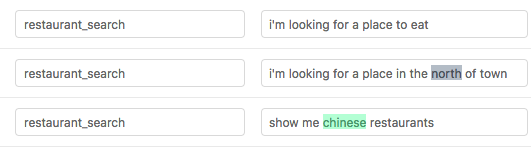
If you use the json format it is strongly recommended that you view your training data in the GUI before training.
Generating More Entity Examples¶
It is sometimes helpful to generate a bunch of entity examples, for example if you have a database of restaurant names. There are a couple of great tools built by the community to help with that.
You can use Chatito , a tool for generating training datasets in rasa’s format using a simple DSL or Tracy, a simple GUI to create training datasets for rasa.
Common Examples¶
Common examples have three components: text, intent, and entities. The first two are strings while the last one is an array.
- The text is the search query; An example of what would be submitted for parsing. [required]
- The intent is the intent that should be associated with the text. [optional]
- The entities are specific parts of the text which need to be identified. [optional]
Entities are specified with a start and end value, which together make a python
style range to apply to the string, e.g. in the example below, with text="show me chinese
restaurants", then text[8:15] == 'chinese'. Entities can span multiple words, and in
fact the value field does not have to correspond exactly to the substring in your example.
That way you can map synonyms, or misspellings, to the same value.
{
"text": "show me chinese restaurants",
"intent": "restaurant_search",
"entities": [
{
"start": 8,
"end": 15,
"value": "chinese",
"entity": "cuisine"
}
]
}
Entity Synonyms¶
If you define entities as having the same value they will be treated as synonyms. Here is an example of that:
[
{
"text": "in the center of NYC",
"intent": "search",
"entities": [
{
"start": 17,
"end": 20,
"value": "New York City",
"entity": "city"
}
]
},
{
"text": "in the centre of New York City",
"intent": "search",
"entities": [
{
"start": 17,
"end": 30,
"value": "New York City",
"entity": "city"
}
]
}
]
as you can see, the entity city has the value New York City in both examples, even though the text in the first
example states NYC. By defining the value attribute to be different from the value found in the text between start
and end index of the entity, you can define a synonym. Whenever the same text will be found, the value will use the
synonym instead of the actual text in the message.
To use the synonyms defined in your training data, you need to make sure the pipeline contains the ner_synonyms
component (see Pipeline and Component Configuration).
Alternatively, you can add an “entity_synonyms” array to define several synonyms to one entity value. Here is an example of that:
{
"rasa_nlu_data": {
"entity_synonyms": [
{
"value": "New York City",
"synonyms": ["NYC", "nyc", "the big apple"]
}
]
}
}
Note
Please note that adding synonyms using the above format does not improve the model’s classification of those entities. Entities must be properly classified before they can be replaced with the synonym value.
Regular Expression Features¶
Regular expressions can be used to support the intent classification and entity extraction. E.g. if your entity has a certain structure as in a zipcode, you can use a regular expression to ease detection of that entity. For the zipcode example it might look like this:
{
"rasa_nlu_data": {
"regex_features": [
{
"name": "zipcode",
"pattern": "[0-9]{5}"
},
{
"name": "greet",
"pattern": "hey[^\\s]*"
},
]
}
}
The name doesn’t define the entity nor the intent, it is just a human readable description for you to remember what this regex is used for and is the title of the corresponding pattern feature. As you can see in the above example, you can also use the regex features to improve the intent classification performance.
Try to create your regular expressions in a way that they match as few words as possible. E.g. using hey[^\s]*
instead of hey.*, as the later one might match the whole message whereas the first one only matches a single word.
Regex features for entity extraction are currently only supported by the ner_crf component! Hence, other entity
extractors, like ner_mitie or ner_spacy won’t use the generated features and their presence will not improve entity recognition
for these extractors. Currently, all intent classifiers make use of available regex features.
Note
Regex features don’t define entities nor intents! They simply provide patterns to help the classifier recognize entities and related intents. Hence, you still need to provide intent & entity examples as part of your training data!
Organization¶
The training data can either be stored in a single file or split into multiple files.
This can make it easier to keep things organised, or to share data between projects.
For example, if you have a restaurant bot which can also handle some basic smalltalk,
you could have a folder called nlu_data:
nlu_data/
├── restaurants.md
├── smalltalk.md
To train a model with this data, pass the path to the directory to the train script:
$ python -m rasa_nlu.train \
--config config.yml \
--data nlu_data/ \
--path projects
Note
Splitting the training data into multiple files currently only works for markdown and JSON data. For other file formats you have to use the single-file approach. You also cannot mix markdown and json