Managing Training Data¶
Syncing Training Data¶
Goal¶
Conversational AI projects require collaboration between at least a product owner and a developer. The Rasa Platform is intended to facilitate this.
A typical workflow looks like this:
- The product owner adds some new training data (usually in the web interface)
- The developer fetches the latest version of the training data
- The developer trains a new model and tests its performance
- The developer updates the deployed bot to use the latest model.
Adding new Training Data¶
There are two ways to add training data in the web interface. In the /inbox view, a user with sufficient permission can create training data by checking (and if necessary, correcting) predictions made by Rasa NLU. In addition, brand new examples can be created by clicking the New button in the /data view.
Fetching the Latest Training Data¶
As a developer, you will want to fetch the latest training data from the running server. To do this, click the ‘download training data’ button. Then train and test a Rasa NLU model on your development machine.
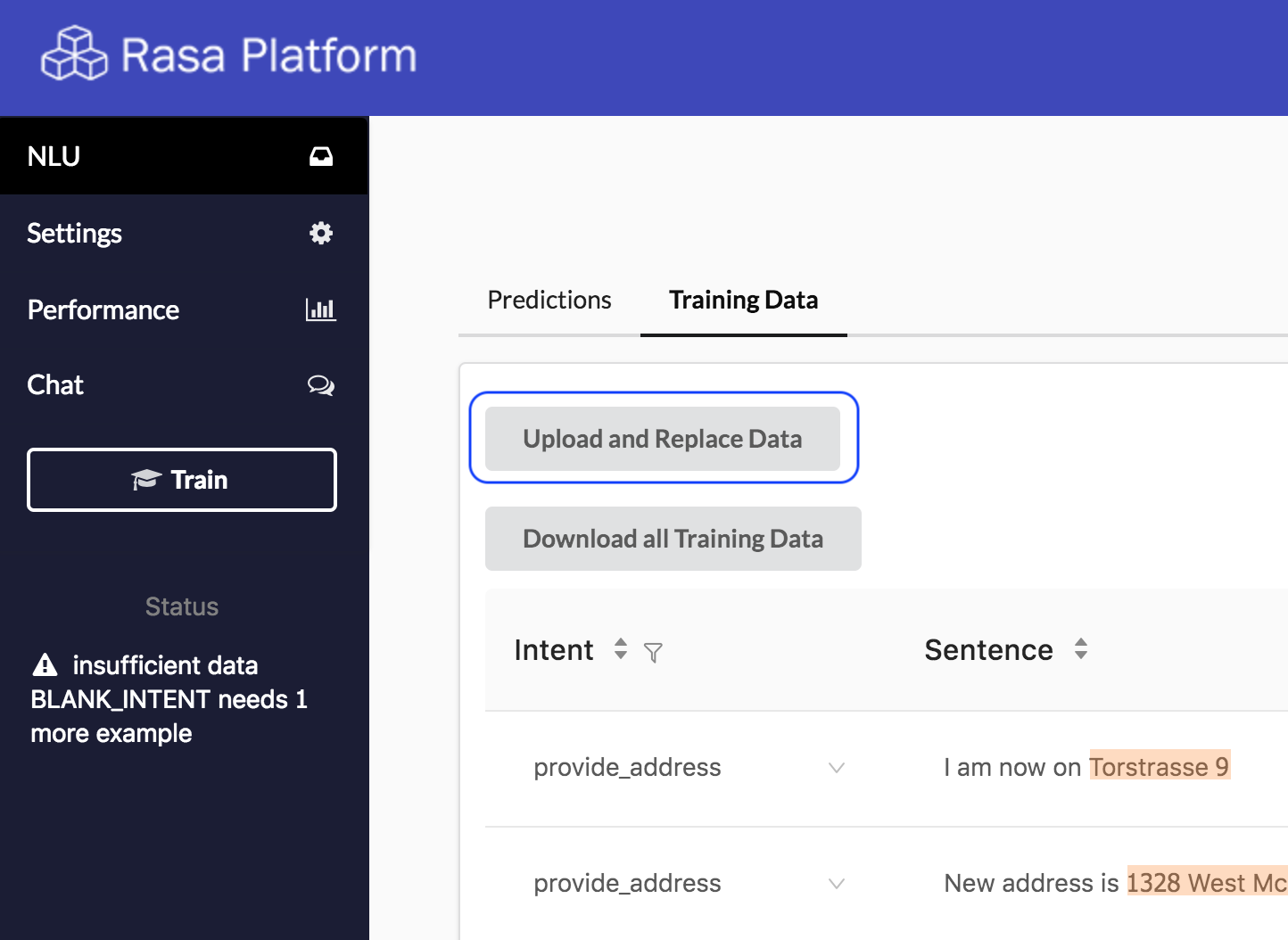
Pushing Training Data to the Server¶
Upload your new Training Data using the ‘upload data’ button. Make sure you have
specified the NLU configuration under the “Settings” tab, this will be similar to
the nlu_config.json (see NLU docs) you use
to train the model locally. The difference is that here you only enter the
information directly relevant to how you want the nlu model to be trained, for
example:
{
"pipeline": "spacy_sklearn",
"path" : "./projects",
"language": "en_core_web_sm"
}
Then press ‘train’ to train the latest model on the server.
Note
Uploading a training data file will replace the existing training data with the data in your file.
As soon as training is completed, Rasa NLU will start fulfilling requests with the latest model.
Creating Entity Training Data¶
In this tutorial, we will show you how to create Rasa NLU training data by sampling entity examples over template sentences.
Installing rasa_extensions¶
Install Rasa Extensions by running pip install rasa_extensions. For more information, please head over to Python package installation.
Note
The rasa_extensions version has to be at least 0.8.2.
What do you need?¶
You need to create a .yaml with the following components:
- sentences - You can supply one or more template sentences. Each sentence has to contain a “_”, which serves as a placeholder for the entity
- intent - The name of the NLU intent
- entity - The name of the entity
- examples - Supply on ore more entity examples in this section. Every example should have one entity value and one or more comma-separated tokens
Example¶
Let’s look at a specific example. The .yaml below contains all of the
components mentioned before.
sentences:
- I would like to order some _
- could I have some _
- i am really craving _
intent: search_restaurant
entity: cuisine
examples:
- value: chinese
tokens: chinese, chianese, chow mein
- value: mexican
tokens: mexican, burritos, enchiladas
- value: italian
tokens: pizza, pasta, italian, risotto
The training examples generated from this file will be of the form
{
"text": "i am really craving chow mein",
"intent": "search_restaurant",
"entities": [
{
"start": 20,
"end": 30,
"value": "chinese",
"entity": "cuisine"
}
]
}
Running the Entity Trainer Module¶
Assuming you have created and saved a .yaml file, you can now go ahead and
run the module to create the training data.
The module takes three parameters:
-y(required): the name of the.yamlfile containing the entity data, e.g.entities.yaml-o(optional): the name of the output file. By default, the training data are saved asentity_training_data.json-s(optional): The fraction of sentences that are randomly sampled for every token. By default, the sampling fraction is 0.5. If the-sparameter is set to 1, all possible combinations of sentences, values and tokens will be generated.
Assuming you have saved your entity data as entities.yaml, run the module in your command line with
python -m rasa_extensions.nlu.entity_trainer -y entities.yaml