Processing Pipeline¶
The process of incoming messages is split into different components. These components are executed one after another in a so called processing pipeline. There are components for entity extraction, for intent classification, pre-processing and there will be many more in the future.
Each component processes the input and creates an output. The ouput can be used by any component that comes after
this component in the pipeline. There are components which only produce information that is used by other components
in the pipeline and there are other components that produce Output attributes which will be returned after
the processing has finished. For example, for the sentence "I am looking for Chinese food" the output
{
"text": "I am looking for Chinese food",
"entities": [
{"start": 8, "end": 15, "value": "chinese", "entity": "cuisine", "extractor": "ner_crf"}
],
"intent": {"confidence": 0.6485910906220309, "name": "restaurant_search"},
"intent_ranking": [
{"confidence": 0.6485910906220309, "name": "restaurant_search"},
{"confidence": 0.1416153159565678, "name": "affirm"}
]
}
is created as a combination of the results of the different components in the pre-configured pipeline spacy_sklearn.
For example, the entities attribute is created by the ner_crf component.
Pre-configured Pipelines¶
To ease the burden of coming up with your own processing pipelines, we provide a couple of ready to use templates
which can be used by settings the pipeline configuration value to the name of the template you want to use.
Here is a list of the existing templates:
| template name | corresponding pipeline |
|---|---|
| spacy_sklearn | ["nlp_spacy", "tokenizer_spacy", "intent_entity_featurizer_regex", "intent_featurizer_spacy", "ner_crf", "ner_synonyms", "intent_classifier_sklearn"] |
| mitie | ["nlp_mitie", "tokenizer_mitie", "ner_mitie", "ner_synonyms", "intent_entity_featurizer_regex", "intent_classifier_mitie"] |
| mitie_sklearn | ["nlp_mitie", "tokenizer_mitie", "ner_mitie", "ner_synonyms", "intent_entity_featurizer_regex", "intent_featurizer_mitie", "intent_classifier_sklearn"] |
| keyword | ["intent_classifier_keyword"] |
Creating your own pipelines is possible by directly passing the names of the components to rasa NLU in the pipeline
configuration variable, e.g. "pipeline": ["nlp_spacy", "ner_crf", "ner_synonyms"]. This creates a pipeline
that only does entity recognition, but no intent classification. Hence, the output will not contain any useful intents.
Built-in Components¶
Short explanation of every components and it’s attributes. If you are looking for more details, you should have
a look at the corresponding source code for the component. Output describes, what each component adds to the final
output result of processing a message. If no output is present, the component is most likely a preprocessor for another
component.
nlp_mitie¶
| Short: | MITIE initializer |
|---|---|
| Outputs: | nothing |
| Description: | Initializes mitie structures. Every mitie component relies on this, hence this should be put at the beginning of every pipeline that uses any mitie components. |
nlp_spacy¶
| Short: | spacy language initializer |
|---|---|
| Outputs: | nothing |
| Description: | Initializes spacy structures. Every spacy component relies on this, hence this should be put at the beginning of every pipeline that uses any spacy components. |
intent_featurizer_mitie¶
| Short: | MITIE intent featurizer |
|---|---|
| Outputs: | nothing, used used as an input to intent classifiers that need intent features (e.g. |
| Description: | Creates feature for intent classification using the MITIE featurizer. Note NOT used by the |
intent_featurizer_spacy¶
| Short: | spacy intent featurizer |
|---|---|
| Outputs: | nothing, used used as an input to intent classifiers that need intent features (e.g. intent_classifier_sklearn) |
| Description: | Creates feature for intent classification using the spacy featurizer. |
intent_featurizer_ngrams¶
| Short: | Appends char-ngram features to feature vector |
|---|---|
| Outputs: | nothing, appends its features to an existing feature vector generated by another intent featurizer |
| Description: | This featurizer appends character ngram features to a feature vector. During training the component looks for the
most common character sequences (e.g. Note There needs to be another intent featurizer previous to this one in the pipeline! |
intent_classifier_keyword¶
| Short: | Simple keyword matching intent classifier. |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.98343}
}
|
| Description: | This classifier is mostly used as a placeholder. It is able to recognize hello and goodbye intents by searching for these keywords in the passed messages. |
intent_classifier_mitie¶
| Short: | MITIE intent classifier (using a text categorizer) |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.98343}
}
|
| Description: | This classifier uses MITIE to perform intent classification. The underlying classifier is using a multi class linear SVM with a sparse linear kernel (see mitie trainer code). |
intent_classifier_sklearn¶
| Short: | sklearn intent classifier |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.78343},
"intent_ranking": [
{
"confidence": 0.1485910906220309,
"name": "goodbye"
},
{
"confidence": 0.08161531595656784,
"name": "restaurant_search"
}
]
}
|
| Description: | The sklearn intent classifier trains a linear SVM which gets optimized using a grid search. In addition to other classifiers it also provides rankings of the labels that did not “win”. The spacy intent classifier needs to be preceded by a featurizer in the pipeline. This featurizer creates the features used for the classification. |
intent_entity_featurizer_regex¶
| Short: | regex feature creation to support intent and entity classification |
|---|---|
| Outputs: | text_features and tokens.pattern |
| Description: | During training, the regex intent featurizer creates a list of regular expressions defined in the training data format.
If an expression is found in the input, a feature will be set, that will later be fed into intent classifier / entity
extractor to simplify classifcation (assuming the classifier has learned during the training phase, that this set
feature indicates a certain intent). Regex features for entity extraction are currently only supported by the
ner_crf component! |
tokenizer_whitespace¶
| Short: | Tokenizer using whitespaces as a separator |
|---|---|
| Outputs: | nothing |
| Description: | Creates a token for every whitespace separated character sequence. Can be used to define tokesn for the MITIE entity extractor. |
tokenizer_mitie¶
| Short: | Tokenizer using MITIE |
|---|---|
| Outputs: | nothing |
| Description: | Creates tokens using the MITIE tokenizer. Can be used to define tokens for the MITIE entity extractor. |
tokenizer_spacy¶
| Short: | Tokenizer using spacy |
|---|---|
| Outputs: | nothing |
| Description: | Creates tokens using the spacy tokenizer. Can be used to define tokens for the MITIE entity extractor. |
ner_mitie¶
| Short: | MITIE entity extraction (using a mitie ner trainer) |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"value": "New York City",
"start": 20,
"end": 33,
"entity": "city",
"extractor": "ner_mitie"}]
}
|
| Description: | This uses the MITIE entitiy extraction to find entities in a message. The underlying classifier is using a multi class linear SVM with a sparse linear kernel and custom features. |
ner_spacy¶
| Short: | spacy entity extraction |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"value": "New York City",
"start": 20,
"end": 33,
"entity": "city",
"extractor": "ner_spacy"}]
}
|
| Description: | Using spacy this component predicts the entities of a message. spacy uses a statistical BILUO transition model. As of now, this component can only use the spacy builtin entity extraction models and can not be retrained. |
ner_synonyms¶
| Short: | Maps synonymous entity values to the same value. |
|---|---|
| Outputs: | modifies existing entities that previous entity extraction components found |
| Description: | If the training data contains defined synonyms (by using the [{
"text": "I moved to New York City",
"intent": "inform_relocation",
"entities": [{"value": "nyc",
"start": 11,
"end": 24,
"entity": "city",
"extractor" "ner_mitie",
"processor": ["ner_synonyms"]}]
},
{
"text": "I got a new flat in NYC.",
"intent": "inform_relocation",
"entities": [{"value": "nyc",
"start": 20,
"end": 23,
"entity": "city",
"extractor" "ner_mitie",
"processor": ["ner_synonyms"]}]
}]
this component will allow you to map the entities |
ner_crf¶
| Short: | conditional random field entity extraction |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"value":"New York City",
"start": 20,
"end": 33,
"entity": "city",
"extractor": "ner_crf"}]
}
|
| Description: | This component implements conditional random fields to do named entity recognition. CRFs can be thought of as an undirected Markov chain where the time steps are words and the states are entity classes. Features of the words (capitalisation, POS tagging, etc.) give probabilities to certain entity classes, as are transitions between neighbouring entity tags: the most likely set of tags is then calculated and returned. |
ner_duckling¶
| Short: | Adds duckling support to the pipeline to unify entity types (e.g. to retrieve common date / number formats) |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"end": 53,
"entity": "time",
"start": 48,
"value": "2017-04-10T00:00:00.000+02:00",
"extractor": "ner_duckling"}]
}
|
| Description: | Duckling allows to recognize dates, numbers, distances and other structured entities
and normalizes them (for a reference of all available entities
see the duckling documentation).
The component recognizes the entity types defined by the duckling dimensions configuration variable.
Please be aware that duckling tries to extract as many entity types as possible without
providing a ranking. For example, if you specify both |
Creating new Components¶
Currently you need to rely on the components that are shipped with rasa NLU, but we plan to add the possibility to
create your own components in your code. Nevertheless, we are looking forward to your contribution of a new component
(e.g. a component to do sentiment analysis). A glimpse into the code of rasa_nlu.components.Component will reveal
which functions need to be implemented to create a new component.
Component Lifecycle¶
Every component can implement several methods from the Component base class; in a pipeline these different methods
will be called in a specific order. Lets assume, we added the following pipeline to our config:
"pipeline": ["Component A", "Component B", "Last Component"].
The image shows the call order during the training of this pipeline :
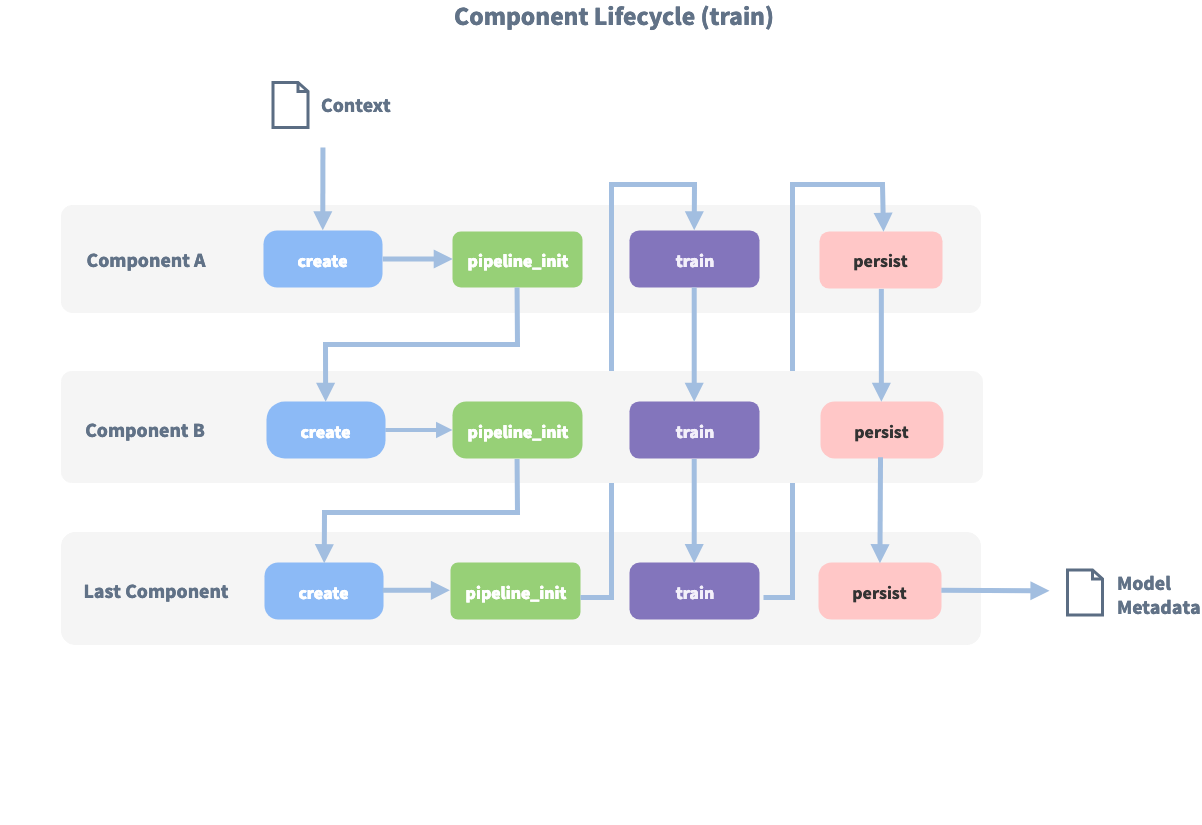
Before the first component is created using the create function, a so called context is created (which is
nothing more than a python dict). This context is used to pass information between the components. For example,
one component can calculate feature vectors for the training data, store that within the context and another
component can retrieve these feature vectors from the context and do intent classification.
Initially the context is filled with all configuration values, the arrows in the image show the call order and visualize the path of the passed context. After all components are trained and persisted, the final context dictionary is used to persist the models metadata.