Choosing a Rasa NLU Pipeline¶
The Short Answer¶
If you have less than 1000 total training examples, and there is a spaCy model for your
language, use the spacy_sklearn pipeline:
language: "en"
pipeline: "spacy_sklearn"
If you have 1000 or more labelled utterances,
use the tensorflow_embedding pipeline:
language: "en"
pipeline: "tensorflow_embedding"
It’s good practice to define the language parameter in your configuration, but
for the tensorflow_embedding pipeline this parameter doesn’t affect anything.
A Longer Answer¶
The two most important pipelines are tensorflow_embedding and spacy_sklearn.
The biggest difference between them is that the spacy_sklearn pipeline uses pre-trained
word vectors from either GloVe or fastText. Instead, the tensorflow embedding pipeline
doesn’t use any pre-trained word vectors, but instead fits these specifically for your dataset.
The advantage of the spacy_sklearn pipeline is that if you have a training example like:
“I want to buy apples”, and Rasa is asked to predict the intent for “get pears”, your model
already knows that the words “apples” and “pears” are very similar. This is especially useful
if you don’t have very much training data.
The advantage of the tensorflow_embedding pipeline is that your word vectors will be customised
for your domain. For example, in general English, the word “balance” is closely related to “symmetry”,
but very different to the word “cash”. In a banking domain, “balance” and “cash” are closely related
and you’d like your model to capture that. This pipeline doesn’t use a language-specific model,
so it will work with any language that you can tokenize (on whitespace or using a custom tokenizer).
You can read more about this topic here .
There are also the mitie and mitie_sklearn pipelines, which use MITIE as a source of word vectors.
We do not recommend that you use these; they are likely to be deprecated in a future release.
Note
Intent classification is independent of entity extraction. So sometimes NLU will get the intent right but entities wrong, or the other way around. You need to provide enough data for both intents and entities.
Multiple Intents¶
If you want to split intents into multiple labels, e.g. for predicting multiple intents or for modeling hierarchical intent structure, you can only do this with the tensorflow pipeline. To do this, use these flags:
intent_tokenization_flagiftruethe algorithm will split the intent labels into tokens and use a bag-of-words representations for them;intent_split_symbolsets the delimiter string to split the intent labels. Default_
Here is a tutorial on how to use multiple intents in Rasa Core and NLU.
Here’s an example configuration:
language: "en"
pipeline:
- name: "intent_featurizer_count_vectors"
- name: "intent_classifier_tensorflow_embedding"
intent_tokenization_flag: true
intent_split_symbol: "+"
Understanding the Rasa NLU Pipeline¶
In Rasa NLU, incoming messages are processed by a sequence of components. These components are executed one after another in a so-called processing pipeline. There are components for entity extraction, for intent classification, pre-processing, and others. If you want to add your own component, for example to run a spell-check or to do sentiment analysis, check out Custom Components.
Each component processes the input and creates an output. The ouput can be used by any component that comes after
this component in the pipeline. There are components which only produce information that is used by other components
in the pipeline and there are other components that produce Output attributes which will be returned after
the processing has finished. For example, for the sentence "I am looking for Chinese food" the output is:
{
"text": "I am looking for Chinese food",
"entities": [
{"start": 8, "end": 15, "value": "chinese", "entity": "cuisine", "extractor": "ner_crf", "confidence": 0.864}
],
"intent": {"confidence": 0.6485910906220309, "name": "restaurant_search"},
"intent_ranking": [
{"confidence": 0.6485910906220309, "name": "restaurant_search"},
{"confidence": 0.1416153159565678, "name": "affirm"}
]
}
This is created as a combination of the results of the different components in the pre-configured pipeline spacy_sklearn.
For example, the entities attribute is created by the ner_crf component.
Every component can implement several methods from the Component base class; in a pipeline these different methods
will be called in a specific order. Lets assume, we added the following pipeline to our config:
"pipeline": ["Component A", "Component B", "Last Component"].
The image shows the call order during the training of this pipeline :
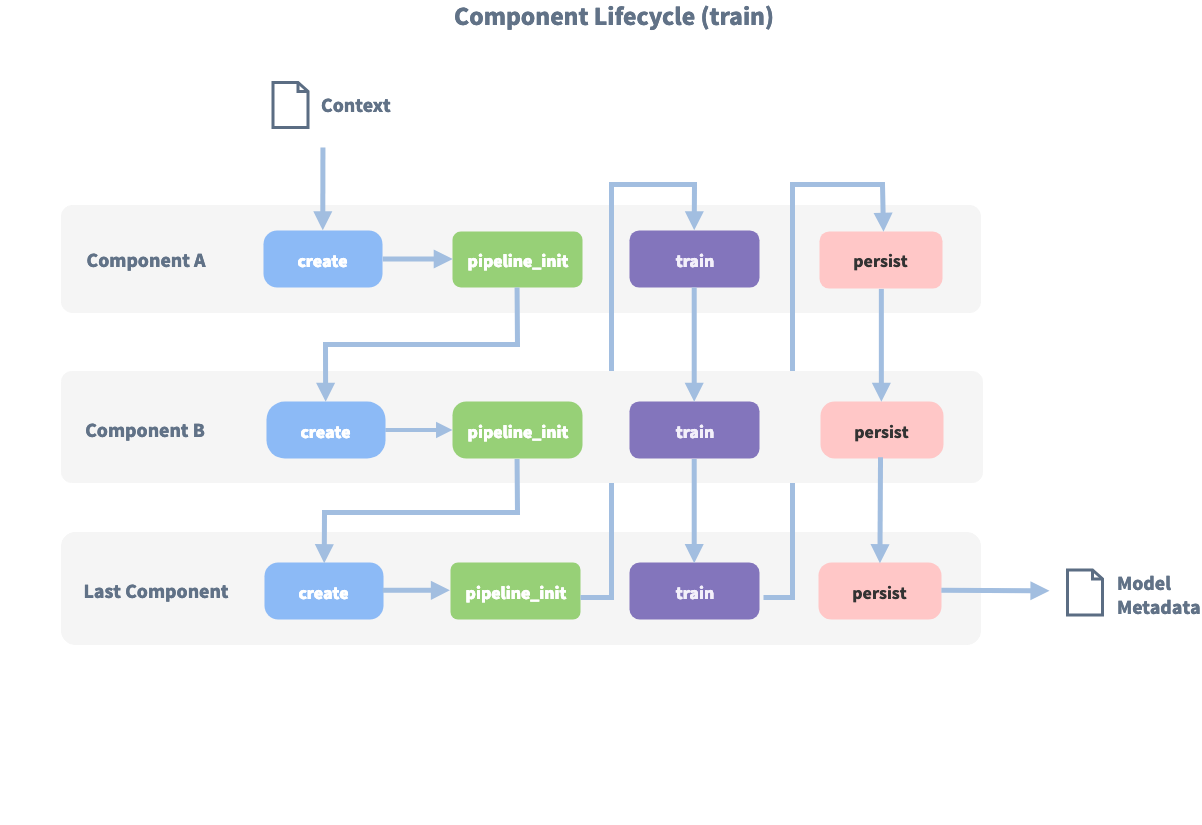
Before the first component is created using the create function, a so called context is created (which is
nothing more than a python dict). This context is used to pass information between the components. For example,
one component can calculate feature vectors for the training data, store that within the context and another
component can retrieve these feature vectors from the context and do intent classification.
Initially the context is filled with all configuration values, the arrows in the image show the call order and visualize the path of the passed context. After all components are trained and persisted, the final context dictionary is used to persist the model’s metadata.
In the object returned after parsing there are two fields that show information
about how the pipeline impacted the entities returned. The extractor field
of an entity tells you which entity extractor found this particular entity.
The processors field contains the name of components that altered this
specific entity.
The use of synonyms can also cause the value field not match the text
exactly. Instead it will return the trained synonym.
{
"text": "show me chinese restaurants",
"intent": "restaurant_search",
"entities": [
{
"start": 8,
"end": 15,
"value": "chinese",
"entity": "cuisine",
"extractor": "ner_crf",
"confidence": 0.854,
"processors": []
}
]
}
Note
The confidence will be set by the CRF entity extractor
(ner_crf component). The duckling entity extractor will always return
1. The ner_spacy extractor does not provide this information and
returns null.
Pre-configured Pipelines¶
A template is just a shortcut for a full list of components. For example, these two configurations are equivalent:
language: "en"
pipeline: "spacy_sklearn"
language: "en"
pipeline:
- name: "nlp_spacy"
- name: "tokenizer_spacy"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_spacy"
- name: "ner_crf"
- name: "ner_synonyms"
- name: "intent_classifier_sklearn"
Below is a list of all the pre-configured pipeline templates.
spacy_sklearn¶
To use spacy as a template:
language: "en"
pipeline: "spacy_sklearn"
See Language Support for possible values for language. To use
the components and configure them separately:
language: "en"
pipeline:
- name: "nlp_spacy"
- name: "tokenizer_spacy"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_spacy"
- name: "ner_crf"
- name: "ner_synonyms"
- name: "intent_classifier_sklearn"
tensorflow_embedding¶
To use it as a template:
language: "en"
pipeline: "tensorflow_embedding"
The tensorflow pipeline supports any language that can be tokenized. The default is to use a simple whitespace tokenizer:
language: "en"
pipeline:
- name: "tokenizer_whitespace"
- name: "ner_crf"
- name: "intent_featurizer_count_vectors"
- name: "intent_classifier_tensorflow_embedding"
If you have a custom tokenizer for your language, you can replace the whitespace tokenizer with something more accurate.
mitie¶
There is no pipeline template, as you need to configure the location of mities featurizer. To use the components and configure them separately:
language: "en"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat"
- name: "tokenizer_mitie"
- name: "ner_mitie"
- name: "ner_synonyms"
- name: "intent_entity_featurizer_regex"
- name: "intent_classifier_mitie"
mitie_sklearn¶
There is no pipeline template, as you need to configure the location of mities featurizer. To use the components and configure them separately:
language: "en"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat"
- name: "tokenizer_mitie"
- name: "ner_mitie"
- name: "ner_synonyms"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_mitie"
- name: "intent_classifier_sklearn"
keyword¶
To use it as a template:
language: "en"
pipeline: "keyword"
To use the components and configure them separately:
language: "en"
pipeline:
- name: "intent_classifier_keyword"
Custom pipelines¶
You don’t have to use a template, you can run a fully custom pipeline by listing the names of the components you want to use:
pipeline:
- name: "nlp_spacy"
- name: "ner_crf"
- name: "ner_synonyms"
This creates a pipeline that only does entity recognition, but no intent classification. So Rasa NLU will not predict any intents. You can find the details of each component in Component Configuration.
If you want to use custom components in your pipeline, see Custom Components.