Pipeline and Component Configuration¶
Contents
- Pipeline and Component Configuration
- Pre-configured Pipelines
- Built-in Components
- nlp_mitie
- nlp_spacy
- intent_featurizer_mitie
- intent_featurizer_spacy
- intent_featurizer_ngrams
- intent_featurizer_count_vectors
- intent_classifier_keyword
- intent_classifier_mitie
- intent_classifier_sklearn
- intent_classifier_tensorflow_embedding
- intent_entity_featurizer_regex
- tokenizer_whitespace
- tokenizer_jieba
- tokenizer_mitie
- tokenizer_spacy
- ner_mitie
- ner_spacy
- ner_synonyms
- ner_crf
- ner_duckling_http
- Component Lifecycle
- Returned Entities Object
Incoming messages are processed by a sequence of components. These components are executed one after another in a so called processing pipeline. There are components for entity extraction, for intent classification, pre-processing, and others. If you want to add your own component, for example to run a spell-check or to do sentiment analysis, check out Custom Components.
Each component processes the input and creates an output. The ouput can be used by any component that comes after
this component in the pipeline. There are components which only produce information that is used by other components
in the pipeline and there are other components that produce Output attributes which will be returned after
the processing has finished. For example, for the sentence "I am looking for Chinese food" the output
{
"text": "I am looking for Chinese food",
"entities": [
{"start": 8, "end": 15, "value": "chinese", "entity": "cuisine", "extractor": "ner_crf", "confidence": 0.864}
],
"intent": {"confidence": 0.6485910906220309, "name": "restaurant_search"},
"intent_ranking": [
{"confidence": 0.6485910906220309, "name": "restaurant_search"},
{"confidence": 0.1416153159565678, "name": "affirm"}
]
}
is created as a combination of the results of the different components in the pre-configured pipeline spacy_sklearn.
For example, the entities attribute is created by the ner_crf component.
Pre-configured Pipelines¶
To ease the burden of coming up with your own processing pipelines, we provide a couple of ready to use templates
which can be used by setting the pipeline configuration value to the name of the template you want to use.
Here is a list of the existing templates:
spacy_sklearn¶
To use spacy as a template:
language: "en"
pipeline: "spacy_sklearn"
See Language Support for possible values for language. To use
the components and configure them separately:
language: "en"
pipeline:
- name: "nlp_spacy"
- name: "tokenizer_spacy"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_spacy"
- name: "ner_crf"
- name: "ner_synonyms"
- name: "intent_classifier_sklearn"
tensorflow_embedding¶
to use it as a template:
language: "en"
pipeline: "tensorflow_embedding"
The tensorflow pipeline supports any language that can be tokenized. The current tokenizer implementation relies on words being separated by spaces, so any languages that adheres to that can be trained with this pipeline.
mitie¶
There is no pipeline template, as you need to configure the location of mities featurizer. To use the components and configure them separately:
language: "en"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat"
- name: "tokenizer_mitie"
- name: "ner_mitie"
- name: "ner_synonyms"
- name: "intent_entity_featurizer_regex"
- name: "intent_classifier_mitie"
mitie_sklearn¶
There is no pipeline template, as you need to configure the location of mities featurizer. To use the components and configure them separately:
language: "en"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat"
- name: "tokenizer_mitie"
- name: "ner_mitie"
- name: "ner_synonyms"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_mitie"
- name: "intent_classifier_sklearn"
keyword¶
to use it as a template:
language: "en"
pipeline: "keyword"
to use the components and configure them separately:
language: "en"
pipeline:
- name: "intent_classifier_keyword"
Multiple Intents¶
If you want to split intents into multiple labels, e.g. for predicting multiple intents or for modeling hierarchical intent structure, use these flags:
intent_tokenization_flagiftruethe algorithm will split the intent labels into tokens and use bag-of-words representations for them;intent_split_symbolsets the delimiter string to split the intent labels. Default_
Here’s an example configuration:
language: "en"
pipeline:
- name: "tokenizer_whitespace"
- name: "ner_crf"
- name: "intent_featurizer_count_vectors"
- name: "intent_classifier_tensorflow_embedding"
intent_tokenization_flag: true
intent_split_symbol: "_"
Custom pipelines¶
Creating your own pipelines is possible by directly passing the names of the ~
components to Rasa NLU in the pipeline configuration variable, e.g.
pipeline:
- name: "nlp_spacy"
- name: "ner_crf"
- name: "ner_synonyms"
This creates a pipeline that only does entity recognition, but no intent classification. Hence, the output will not contain any useful intents.
Built-in Components¶
Short explanation of every components and it’s attributes. If you are looking for more details, you should have
a look at the corresponding source code for the component. Output describes, what each component adds to the final
output result of processing a message. If no output is present, the component is most likely a preprocessor for another
component.
nlp_mitie¶
| Short: | MITIE initializer |
|---|---|
| Outputs: | nothing |
| Description: | Initializes mitie structures. Every mitie component relies on this, hence this should be put at the beginning of every pipeline that uses any mitie components. |
| Configuration: | The MITIE library needs a language model file, that must be specified in the configuration: pipeline:
- name: "nlp_mitie"
# language model to load
model: "data/total_word_feature_extractor.dat"
For more information where to get that file from, head over to Installation. |
nlp_spacy¶
| Short: | spacy language initializer |
|---|---|
| Outputs: | nothing |
| Description: | Initializes spacy structures. Every spacy component relies on this, hence this should be put at the beginning of every pipeline that uses any spacy components. |
| Configuration: | Language model, default will use the configured language.
If the spacy model to be used has a name that is different from the language tag ( pipeline:
- name: "nlp_spacy"
# language model to load
model: "en_core_web_md"
# when retrieving word vectors, this will decide if the casing
# of the word is relevant. E.g. `hello` and `Hello` will
# retrieve the same vector, if set to `false`. For some
# applications and models it makes sense to differentiate
# between these two words, therefore setting this to `true`.
case_sensitive: false
|
intent_featurizer_mitie¶
| Short: | MITIE intent featurizer |
|---|---|
| Outputs: | nothing, used as an input to intent classifiers that need intent features (e.g. |
| Description: | Creates feature for intent classification using the MITIE featurizer. Note NOT used by the |
| Configuration: | pipeline:
- name: "intent_featurizer_mitie"
|
intent_featurizer_spacy¶
| Short: | spacy intent featurizer |
|---|---|
| Outputs: | nothing, used as an input to intent classifiers that need intent features (e.g. intent_classifier_sklearn) |
| Description: | Creates feature for intent classification using the spacy featurizer. |
intent_featurizer_ngrams¶
| Short: | Appends char-ngram features to feature vector |
|---|---|
| Outputs: | nothing, appends its features to an existing feature vector generated by another intent featurizer |
| Description: | This featurizer appends character ngram features to a feature vector. During training the component looks for the
most common character sequences (e.g. Note There needs to be another intent featurizer previous to this one in the pipeline! |
| Configuration: | pipeline:
- name: "intent_featurizer_ngrams"
# Maximum number of ngrams to use when augmenting
# feature vectors with character ngrams
max_number_of_ngrams: 10
|
intent_featurizer_count_vectors¶
| Short: | Creates bag-of-words representation of intent features |
|---|---|
| Outputs: | nothing, used as an input to intent classifiers that
need bag-of-words representation of intent features
(e.g. |
| Description: | Creates bag-of-words representation of intent features using sklearn’s CountVectorizer. All tokens which consist only of digits (e.g. 123 and 99 but not a123d) will be assigned to the same feature. Note If the words in the model language cannot be split by whitespace,
a language-specific tokenizer is required in the pipeline before this component
(e.g. using |
| Configuration: | See sklearn’s CountVectorizer docs for detailed description of the configuration parameters Handling Out-Of-Vacabulary (OOV) words:
pipeline:
- name: "intent_featurizer_count_vectors"
# the parameters are taken from
# sklearn's CountVectorizer
# regular expression for tokens
"token_pattern": r'(?u)\b\w\w+\b'
# remove accents during the preprocessing step
"strip_accents": None # {'ascii', 'unicode', None}
# list of stop words
"stop_words": None # string {'english'}, list, or None (default)
# min document frequency of a word to add to vocabulary
# float - the parameter represents a proportion of documents
# integer - absolute counts
"min_df": 1 # float in range [0.0, 1.0] or int
# max document frequency of a word to add to vocabulary
# float - the parameter represents a proportion of documents
# integer - absolute counts
"max_df": 1.0 # float in range [0.0, 1.0] or int
# set ngram range
"min_ngram": 1 # int
"max_ngram": 1 # int
# limit vocabulary size
"max_features": None # int or None
# if convert all characters to lowercase
"lowercase": true # bool
# handling Out-Of-Vacabulary (OOV) words
# will be converted to lowercase if lowercase is true
"OOV_token": None # string or None
"OOV_words": [] # list of strings
|
intent_classifier_keyword¶
| Short: | Simple keyword matching intent classifier. |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.98343}
}
|
| Description: | This classifier is mostly used as a placeholder. It is able to recognize hello and goodbye intents by searching for these keywords in the passed messages. |
intent_classifier_mitie¶
| Short: | MITIE intent classifier (using a text categorizer) |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.98343}
}
|
| Description: | This classifier uses MITIE to perform intent classification. The underlying classifier is using a multi class linear SVM with a sparse linear kernel (see mitie trainer code). |
| Configuration: | pipeline:
- name: "intent_classifier_mitie"
|
intent_classifier_sklearn¶
| Short: | sklearn intent classifier |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.78343},
"intent_ranking": [
{
"confidence": 0.1485910906220309,
"name": "goodbye"
},
{
"confidence": 0.08161531595656784,
"name": "restaurant_search"
}
]
}
|
| Description: | The sklearn intent classifier trains a linear SVM which gets optimized using a grid search. In addition to other classifiers it also provides rankings of the labels that did not “win”. The spacy intent classifier needs to be preceded by a featurizer in the pipeline. This featurizer creates the features used for the classification. |
| Configuration: | During the training of the SVM a hyperparameter search is run to find the best parameter set. In the config, you can specify the parameters that will get tried pipeline:
- name: "intent_classifier_sklearn"
# Specifies the list of regularization values to
# cross-validate over for C-SVM.
# This is used with the ``kernel`` hyperparameter in GridSearchCV.
C: [1, 2, 5, 10, 20, 100]
# Specifies the kernel to use with C-SVM.
# This is used with the ``C`` hyperparameter in GridSearchCV.
kernels: ["linear"]
|
intent_classifier_tensorflow_embedding¶
| Short: | Embedding intent classifier |
|---|---|
| Outputs: |
|
| Output-Example: | {
"intent": {"name": "greet", "confidence": 0.8343},
"intent_ranking": [
{
"confidence": 0.385910906220309,
"name": "goodbye"
},
{
"confidence": 0.28161531595656784,
"name": "restaurant_search"
}
]
}
|
| Description: | The embedding intent classifier embeds user inputs and intent labels into the same space. Supervised embeddings are
trained by maximizing similarity between them. This algorithm is based on
the starspace idea from: https://arxiv.org/abs/1709.03856. However, in this implementation
the The embedding intent classifier needs to be preceded by a featurizer in the pipeline.
This featurizer creates the features used for the embeddings.
It is recommended to use Note If during prediction time a message contains only words unseen during training,
and no Out-Of-Vacabulary preprocessor was used,
empty intent |
| Configuration: | If you want to split intents into multiple labels, e.g. for predicting multiple intents or for modeling hierarchical intent structure, use these flags:
Note For Note There is an option to use linearly increasing batch size. The idea comes from https://arxiv.org/abs/1711.00489.
In order to do it pass a list to In the config, you can specify these parameters: pipeline:
- name: "intent_classifier_tensorflow_embedding"
# nn architecture
"num_hidden_layers_a": 2
"hidden_layer_size_a": [256, 128]
"num_hidden_layers_b": 0
"hidden_layer_size_b": []
"batch_size": [64, 256]
"epochs": 300
# embedding parameters
"embed_dim": 20
"mu_pos": 0.8 # should be 0.0 < ... < 1.0 for 'cosine'
"mu_neg": -0.4 # should be -1.0 < ... < 1.0 for 'cosine'
"similarity_type": "cosine" # string 'cosine' or 'inner'
"num_neg": 20
"use_max_sim_neg": true # flag which loss function to use
# regularization
"C2": 0.002
"C_emb": 0.8
"droprate": 0.2
# flag if to tokenize intents
"intent_tokenization_flag": false
"intent_split_symbol": "_"
# visualization of accuracy
"evaluate_every_num_epochs": 10 # small values may hurt performance
"evaluate_on_num_examples": 1000 # large values may hurt performance
Note Parameter |
intent_entity_featurizer_regex¶
| Short: | regex feature creation to support intent and entity classification |
|---|---|
| Outputs: | text_features and tokens.pattern |
| Description: | During training, the regex intent featurizer creates a list of regular expressions defined in the training data format.
For each regex, a feature will be set marking whether this expression was found in the input, which will later be fed into intent classifier / entity
extractor to simplify classification (assuming the classifier has learned during the training phase, that this set
feature indicates a certain intent). Regex features for entity extraction are currently only supported by the
ner_crf component!
.. note:: There needs to be a tokenizer previous to this featurizer in the pipeline! |
tokenizer_whitespace¶
| Short: | Tokenizer using whitespaces as a separator |
|---|---|
| Outputs: | nothing |
| Description: | Creates a token for every whitespace separated character sequence. Can be used to define tokens for the MITIE entity extractor. |
tokenizer_jieba¶
| Short: | Tokenizer using Jieba for Chinese language |
|---|---|
| Outputs: | nothing |
| Description: | Creates tokens using the Jieba tokenizer specifically for Chinese
language. For language other than Chinese, Jieba will work as
|
| Configuration: | User’s custom dictionary files can be auto loaded by specific the files’ directory path via pipeline:
- name: "tokenizer_jieba"
dictionary_path: "path/to/custom/dictionary/dir" # or None (which is default value) means don't use custom dictionaries
|
tokenizer_mitie¶
| Short: | Tokenizer using MITIE |
|---|---|
| Outputs: | nothing |
| Description: | Creates tokens using the MITIE tokenizer. Can be used to define tokens for the MITIE entity extractor. |
| Configuration: | pipeline:
- name: "tokenizer_mitie"
|
tokenizer_spacy¶
| Short: | Tokenizer using spacy |
|---|---|
| Outputs: | nothing |
| Description: | Creates tokens using the spacy tokenizer. Can be used to define tokens for the MITIE entity extractor. |
ner_mitie¶
| Short: | MITIE entity extraction (using a mitie ner trainer) |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"value": "New York City",
"start": 20,
"end": 33,
"confidence": null,
"entity": "city",
"extractor": "ner_mitie"}]
}
|
| Description: | This uses the MITIE entitiy extraction to find entities in a message. The underlying classifier is using a multi class linear SVM with a sparse linear kernel and custom features. The MITIE component does not provide entity confidence values. |
| Configuration: | pipeline:
- name: "ner_mitie"
|
ner_spacy¶
| Short: | spacy entity extraction |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"value": "New York City",
"start": 20,
"end": 33,
"entity": "city",
"confidence": null,
"extractor": "ner_spacy"}]
}
|
| Description: | Using spacy this component predicts the entities of a message. spacy uses a statistical BILOU transition model. As of now, this component can only use the spacy builtin entity extraction models and can not be retrained. This extractor does not provide any confidence scores. |
ner_synonyms¶
| Short: | Maps synonymous entity values to the same value. |
|---|---|
| Outputs: | modifies existing entities that previous entity extraction components found |
| Description: | If the training data contains defined synonyms (by using the [{
"text": "I moved to New York City",
"intent": "inform_relocation",
"entities": [{"value": "nyc",
"start": 11,
"end": 24,
"entity": "city",
}]
},
{
"text": "I got a new flat in NYC.",
"intent": "inform_relocation",
"entities": [{"value": "nyc",
"start": 20,
"end": 23,
"entity": "city",
}]
}]
this component will allow you to map the entities |
ner_crf¶
| Short: | conditional random field entity extraction |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"value":"New York City",
"start": 20,
"end": 33,
"entity": "city",
"confidence": 0.874,
"extractor": "ner_crf"}]
}
|
| Description: | This component implements conditional random fields to do named entity recognition. CRFs can be thought of as an undirected Markov chain where the time steps are words and the states are entity classes. Features of the words (capitalisation, POS tagging, etc.) give probabilities to certain entity classes, as are transitions between neighbouring entity tags: the most likely set of tags is then calculated and returned. If POS features are used (pos or pos2), spaCy has to be installed. |
| Configuration: | pipeline:
- name: "ner_crf"
# The features are a ``[before, word, after]`` array with
# before, word, after holding keys about which
# features to use for each word, for example, ``"title"``
# in array before will have the feature
# "is the preceding word in title case?".
# Available features are:
# ``low``, ``title``, ``suffix5``, ``suffix3``, ``suffix2``,
# ``suffix1``, ``pos``, ``pos2``, ``prefix5``, ``prefix2``,
# ``bias``, ``upper`` and ``digit``
features: [["low", "title"], ["bias", "suffix3"], ["upper", "pos", "pos2"]]
# The flag determines whether to use BILOU tagging or not. BILOU
# tagging is more rigorous however
# requires more examples per entity. Rule of thumb: use only
# if more than 100 examples per entity.
BILOU_flag: true
# This is the value given to sklearn_crfcuite.CRF tagger before training.
max_iterations: 50
# This is the value given to sklearn_crfcuite.CRF tagger before training.
# Specifies the L1 regularization coefficient.
L1_c: 0.1
# This is the value given to sklearn_crfcuite.CRF tagger before training.
# Specifies the L2 regularization coefficient.
L2_c: 0.1
|
ner_duckling_http¶
| Short: | Duckling lets you extract common entities like dates, amounts of money, distances, and others in a number of languages. |
|---|---|
| Outputs: | appends |
| Output-Example: | {
"entities": [{"end": 53,
"entity": "time",
"start": 48,
"value": "2017-04-10T00:00:00.000+02:00",
"confidence": 1.0,
"extractor": "ner_duckling_http"}]
}
|
| Description: | To use this component you need to run a duckling server. The easiest
option is to spin up a docker container using
Alternatively, you can install duckling directly on your machine and start the server. Duckling allows to recognize dates, numbers, distances and other structured entities
and normalizes them (for a reference of all available entities
see the duckling documentation).
Please be aware that duckling tries to extract as many entity types as possible without
providing a ranking. For example, if you specify both |
| Configuration: | Configure which dimensions, i.e. entity types, the duckling component to extract. A full list of available dimensions can be found in the duckling documentation. pipeline:
- name: "ner_duckling_http"
# url of the running duckling server
url: "http://localhost:8000"
# dimensions to extract
dimensions: ["time", "number", "amount-of-money", "distance"]
# allows you to configure the locale, by default the language is
# used
locale: "de_DE"
# if not set the default timezone of Duckling is going to be used
# needed to calculate dates from relative expressions like "tomorrow"
timezone: "Europe/Berlin"
|
Component Lifecycle¶
Every component can implement several methods from the Component base class; in a pipeline these different methods
will be called in a specific order. Lets assume, we added the following pipeline to our config:
"pipeline": ["Component A", "Component B", "Last Component"].
The image shows the call order during the training of this pipeline :
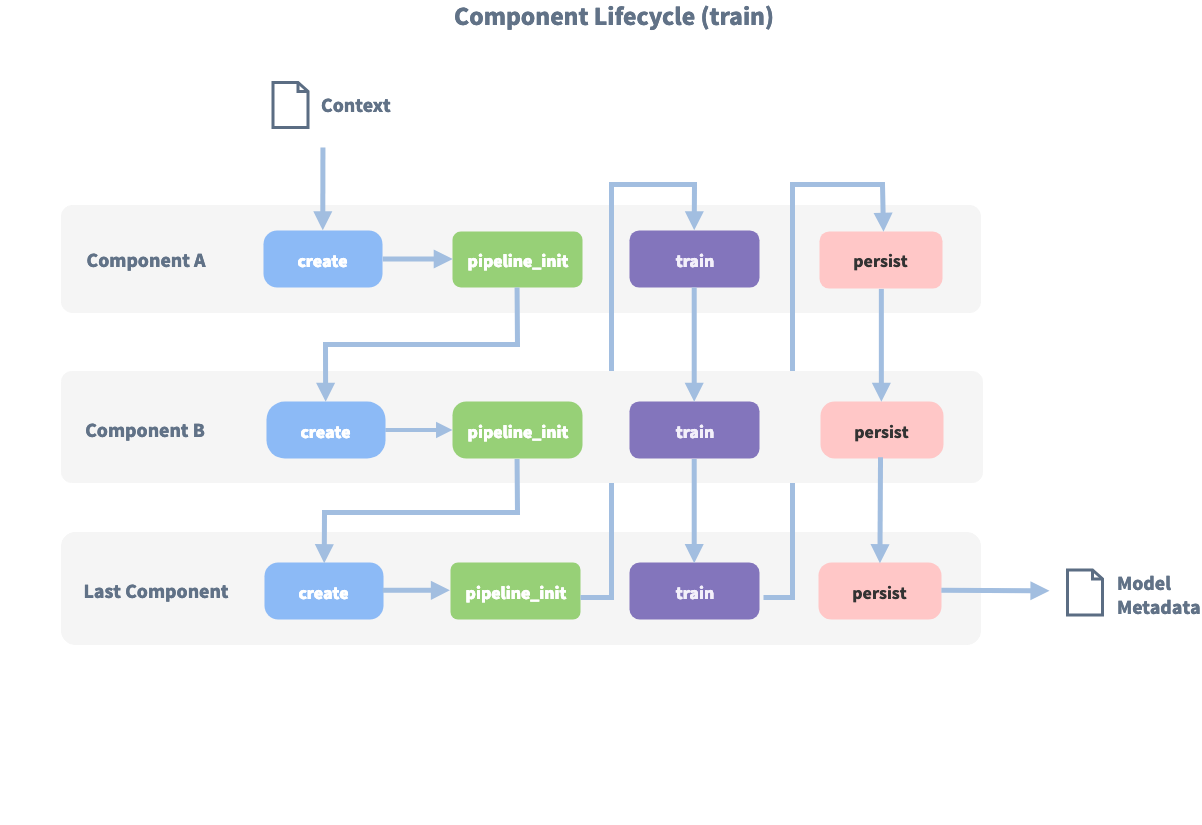
Before the first component is created using the create function, a so called context is created (which is
nothing more than a python dict). This context is used to pass information between the components. For example,
one component can calculate feature vectors for the training data, store that within the context and another
component can retrieve these feature vectors from the context and do intent classification.
Initially the context is filled with all configuration values, the arrows in the image show the call order and visualize the path of the passed context. After all components are trained and persisted, the final context dictionary is used to persist the model’s metadata.
Returned Entities Object¶
In the object returned after parsing there are two fields that show information
about how the pipeline impacted the entities returned. The extractor field
of an entity tells you which entity extractor found this particular entity.
The processors field contains the name of components that altered this
specific entity.
The use of synonyms can also cause the value field not match the text
exactly. Instead it will return the trained synonym.
{
"text": "show me chinese restaurants",
"intent": "restaurant_search",
"entities": [
{
"start": 8,
"end": 15,
"value": "chinese",
"entity": "cuisine",
"extractor": "ner_crf",
"confidence": 0.854,
"processors": []
}
]
}
Note
The confidence will be set by the CRF entity extractor (ner_crf component). The duckling entity extractor will always return 1. The ner_spacy extractor does not provide this information and returns null.